Your Distributed Monoliths are secretly plotting against you

Every now and then, I ask myself the same question.
What important truth do very few people agree with you on? — Peter Thiel
Before writing this, I spent a lot of time applying this question to a topic that’s very trendy nowadays, microservices. I believe I have found some interesting insights, some based on some reflections and others from real experiences, that I will share with you today.
Let’s start with the important truth, our north star, that will guide us on this journey.
Most implementations of microservices are nothing more than distributed monoliths.
The Monolith era
Every system starts with a monolith application. I’m not about to go on and on about it as a lot of people have already written on the subject. However, the grand majority of the content regarding monoliths focuses on aspects such as developer productivity and scalability, leaving behind the most valuable asset of every Internet-based company: data.

If data is so important, why are all the other topics getting all the attention? Well, the answer is simple: because it’s not hurting you as much as the other ones.
The monolith is perhaps the only moment in the life of a system when you:
- Fully understand your data model;
- Are consistent when it comes to data (assuming you’re using an appropriate database for your use case).
From a data perspective, the monolith is ideal. And since data is the most precious asset of every company, you should not break it unless you have a very good reason, or a set of them. Most of the times, the ultimate reason is the need to scale (as a consequence of the physical limitations of the real world).
When this happens, your system will, most likely, enter a new era: the distributed monolith.
The Distributed Monolith Era
Let’s say your company is going well and application needs to evolve. You are getting bigger and bigger clients, and your Billing and Reporting requirements have changed in terms of feature set and volume.
In your crusade to break the monolith, you might end up creating two smaller services for Reporting and Billing. These new services will probably expose an HTTP API and have a dedicated database to persist state. After a lot of commits, you might end up, as we did at Unbabel, with an something similar to the drawing below.

Everything is moving according to plan.
- Your team continues to break your monolith into smaller systems;
- CI/CD pipelines are working like a charm;
- Your Kubernetes cluster is healthy and your engineers feel productive and happy.
Life is great. Everyone is happy.
But what if I told you there’s a secret evil plotting against you?
If you take a closer look into your system now, you’ll realize your data is now spread across different systems. You went from a stage where you had a unique datastore where you had all your data objects, to a stage where your data objects are spread all over the place. You might think that’s not a big issue because the entire purpose of microservices is to create abstractions and conceal data from outside, hiding the underlying complexity of the system.
And you are totally right. But a larger scale brings harder problems: anytime now, your business will have a set of requirements (e.g a specific type of metric) that forces you to access data in more than one system.
What do you do now? Well, there are a lot of options. But you are in a rush to satisfy the big batch of customers you just signed, so you need to find a balance between perfect and done. After some discussions, let’s say you decided to build another system to perform some ETL work that gets the job done. That system will need to have access to all the read replicas that contain the information you need. The figure below depicts how such a system could work.
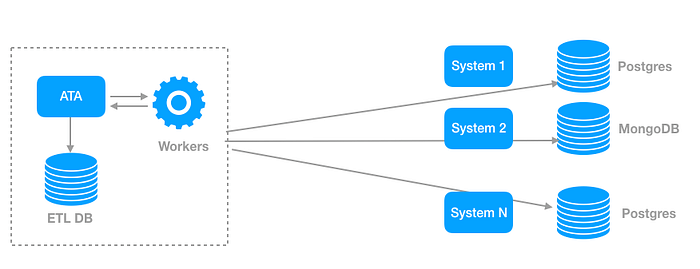
We followed this approach at Unbabel because:
- It has limited impact on the performance of each microservice;
- It requires no big infrastructure changes (just adding a new microservice);
- We were able to answer our business requirements in a short period of time.
From personal experience, I believe this approach works for a while, at a certain scale. At Unbabel, it served us pretty well until recently, when we started facing some challenges. Some of the things that caused us some headaches were:
1. Data changes
One of the biggest advantages of microservices is encapsulation. The internal representation of the data can change and the system’s clients are not affected because they communicate via an external API. However, our strategy required direct access to the internal representation of the data, which means that every time a team made a change on the way data is represented (e.g. renaming a field or changing a type from text to uuid), we had to change and deploy our ETL service.
2. Many different data schemas to handle
As the number of systems we had to connect to increased, we started dealing with a lot of heterogeneous ways of representing data. It became obvious that managing all those schemas, relationships and representations was not going to scale for us.
The root of all evil
In order to get a complete view of what happens in the system, we ended up following an approach that was similar to a monolith. The only difference is that there’s not only one system and a database, but dozens of them, each with their own representation of data and sometimes even with the same data replicated across them.
I call this the distributed monolith. Why? Because in this scenario there’s no way of capturing change across the system, the only way to derive state from the system is to build a service that connects directly to the datastores of all microservices. It’s interesting to see how some Internet behemoths faced similar challenges at some point in their history. A nice example I always give is Linkedin’s.
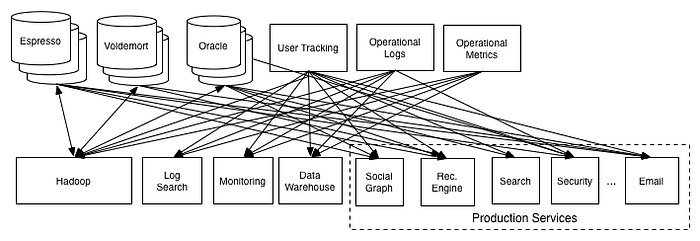
Right about now you may be wondering “how are you guys planning on solving this?” The answer is simple: we need to start capturing changes and keep track of important actions as they happen.
Breaking the Distributed Monolith with Event Sourcing
Much like the rest of the world, Internet systems are driven by actions. A request to an API can lead to inserting a record in a database. Now, most of the times we don’t really care about it because we only consider the update of the database state. The state update is a causal consequence of an event (in this case an API request) that happened. The concept of an event is a simple and yet it’s a very powerful aspect that we can use to break the Distributed Monolith.
An event is nothing more than an immutable fact representing something that happened in your system. In a microservice architecture, events become crucial and allow us to understand the data flows and derive state across multiple systems. Every microservice that performs an action that is of general interest should emit an event with the information relevant to the fact that it represents.
You may be asking
“Why does having microservices emitting events help me with the distributed monolith problem?”
When you have systems emitting events you can have a log of facts that:
- Is not coupled to any datastore: events are usually serialized using binary formats such as JSON, Avro or Protobufs;
- Is immutable: once an event is emitted it cannot be changed;
- Is reproducible: a state of the system, at a given point in time, can be reproduced by replaying the log of events.
With that log you can derive state by processing events using any type of application logic. You are no longer coupled with any set of microservices and their N ways of representing data. The source of truth and your only data source becomes the repository where the events are stored.
Here are some reasons on why I believe having a log of events helps us break the Distributed Monolith:
1. One source of truth
Instead of having N data sources to connect with possibly many different types of databases, in this new design, your source of truth is just one: the event log.
2. Universal data format
In the previous design, we had to deal with many data representations because we were coupled with the database directly. In this new one, we can express ourselves with a lot more flexibility.
Let’s assume you like an Instagram photo some of your friends posted. That action can be described by something like “User X liked Photo P”. This is the event that represents that:
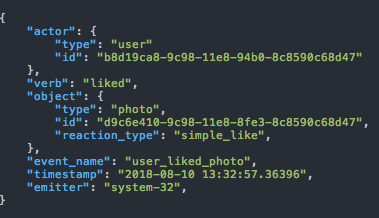
3. Decoupling between producers and consumers
Last but not least, one of the greatest advantages of having events is the effective decoupling of data producers and consumers. This not only allows systems to scale easier but it also reduces dependencies between them. The only contract between systems becomes the event schema.
It all started with a question: What important truth do very few people agree with you on?
Allow me to go back to it as we’re ending this journey. I believe most companies don’t think of their data as a first class citizen when they start their migration to microservices. They claim data changes are still possible via APIs, but that will end up increasing the level of complexity of the service itself.
My claim is that, in a microservice architecture, the only correct way to capture data changes is to have systems emit events that follow a specific contract. With the right event log, you can derive datasets given any number of business requirements — you’re just applying different rules to the same facts. In some cases, these data silos can be avoided if your company (especially your product managers) treats data as a product. But that’s a topic for another conversation, and one that’s going to happen sooner than you think.
Thank you for reading, and I hope you enjoyed it as much as I did writing it.
Code long and prosper!
References:
Talks
Websites and Blogs
Books & Papers
